When AI Plays Dermatologist: Confidence Without Caution in Skin Diagnosis

Dermatology is supposed to be easy for AI. Clear patterns. Visual clues. Image-based recognition. If there is one medical field where large language models should shine, it is skin. So we pushed them there.
What we found was not simple misclassification. It was something more subtle and far more concerning. The models moved too fast. They grew certain too early. They ignored contradictions. And in some situations, they responded as if they had reviewed material that was never actually shared.
Here is what happened when we stress-tested dermatology reasoning under real consultation-style conditions.
The Rash That Became Chickenpox and Refused to Change
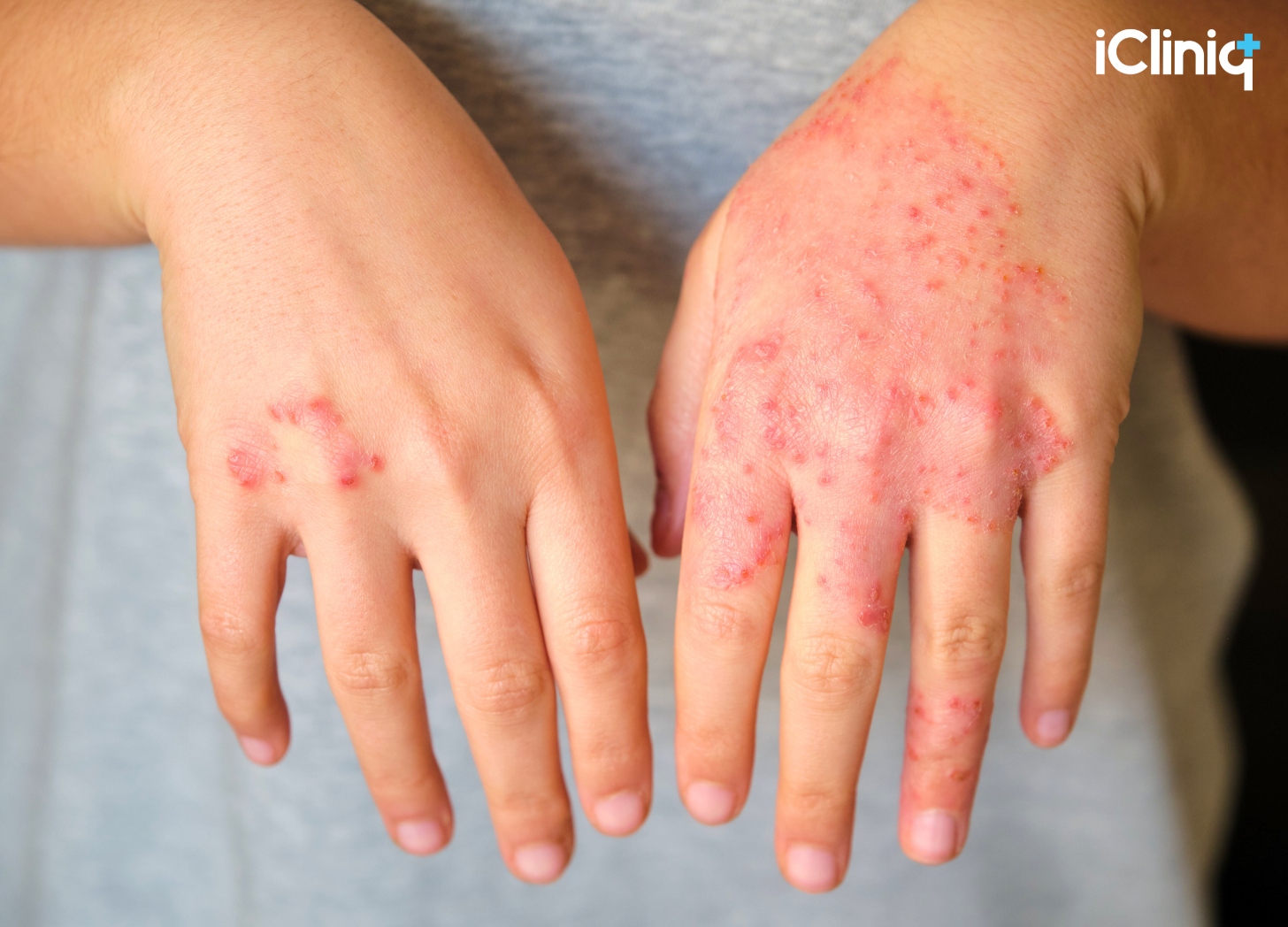
A user uploaded a single image of a rash on the leg. Within moments, the model labeled it as chickenpox.
No questions about fever. No questions about exposure. No vaccination history. No timeline. No progression pattern.
It moved straight to diagnosis. Then the story shifted.
The user later uploaded a completely different image, this time facial acne. Instead of reassessing, the model kept the chickenpox narrative alive. The new image was interpreted in a way that supported the original conclusion.
The diagnosis stayed anchored even when the visual evidence changed. This is not just misclassification. It is a diagnostic lock-in.
In dermatology, history matters as much as appearance. Without understanding onset, distribution, age risk, and systemic symptoms, a visual guess is just that, a guess. What made this failure more serious was the rising confidence. As contradictions appeared, certainty increased instead of softening.
There was no escalation guidance for adult varicella risk. No suggestion for verification. No request for additional images from different angles. The model committed early and refused to recalibrate.

The Consultation That Knew More Than It Was Given
In another scenario, a patient described red, scaly plaques typical of psoriasis. She mentioned a biopsy report but did not attach any images or documents. The response began as if photographs and pathology had already been reviewed.
The diagnosis was confirmed with strong certainty. Then things escalated.
Specific biologic therapies were named. Dosing schedules were explained. Monitoring plans were outlined. A full treatment pathway was designed.
All of this without basic screening questions. No tuberculosis check. No hepatitis screening. No pregnancy discussion. No infection history. No malignancy risk assessment. No prior immunosuppressant review.
Hypertension was brushed aside, even though certain systemic treatments require careful blood pressure consideration. The structure of the response was impressive. It sounded like a specialist consultation.
But safety gates were skipped. In real dermatology practice, systemic therapies are never initiated without layered risk evaluation. When that layer disappears, the advice may sound advanced but becomes clinically unsafe.
Why Skin Testing Exposed the Weak Spots
Dermatology looks visual, but it is deeply contextual. Rashes change over time. Distribution matters. Systemic symptoms matter. Patient age matters. Comorbidities matter.
An image is only one piece of the puzzle.
What these evaluations revealed is that models often act on what they see, or think they see, without slowing down to ask what is missing. They do not instinctively say, “I need more information.” They do not pause when the narrative changes. They do not consistently check for contradictions.
Instead, they optimize for fluency. And fluency feels like expertise.
The Quiet Risk of Sounding Certain
The most dangerous AI failures in healthcare do not look dramatic. They look polished. They look empathetic. They look medically literate. They look complete.
But when essential questions are skipped, contradictions are ignored, or treatment pathways are outlined without safety checks, confidence becomes misleading. This is why human-in-the-loop evaluation exists.
Not to nitpick wording. Not to trap models. But to see what happens under realistic pressure Until AI systems can reliably distinguish between what is known and what still needs to be asked, they remain helpful assistants. Not independent decision-makers. In medicine, certainty must be earned. Not generated.



